
Auto-scaling process is slow on Amazon EKS with NLB
Register target with target group is slow than expected behind the Network Load Balancer

Background
One of my customers wants to build the workloads on Amazon EKS, and plan to leverage Pod AutoScaler to automatically scale the number of pods in a deployment. The LoadBalancer type ahead the target group is NLB (Network Load Balancer) in their use case.
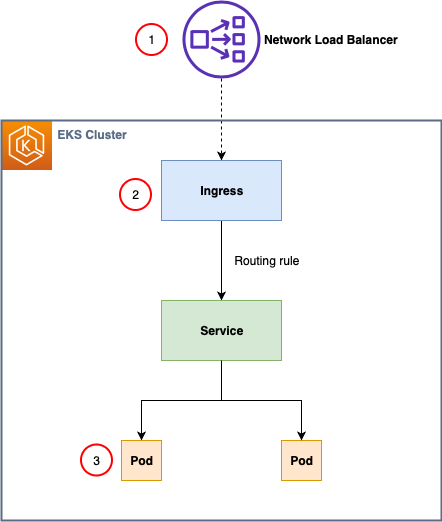
Ingress traffic to Amazon EKS
Customer expects the registration flow of new target should be soon (less than one minute), but the real situation is that it takes minutes before the new provisioned Pod can start to serve traffic.
My gut feeling says it should not be so slow for a new Pod to become healthy status. At first, I have suspected it’s due to the health check interval is too high, so I checked with customer and they have already adjusted to the minimum interval, 10 seconds.
Later I asked customer to open a support case to the support engineer team who can help to dig into the detail of AWS back-end service to know why the provisioned time is longer than expected.
The interesting thing is I suggested them to use ALB (Application Load Balancer), and don’t know why they switch to NLB on the architecture. Finally, I know the reason and they back to use ALB again, but it’s another story we can talk later.
Why ?
As discussed with our support engineer, I realized it’s a known and current a limitation to NLB. But why does the process take so long time ? We can divide the the whole process into few steps,
- When a new target is registered to a Network Load Balancer, it would be stayed on initial state before complete and may be up to 180 seconds to finish.
- After registration is complete and the state become unhealthy, the Network Load Balancer health check systems start to send health checks to the target.
- Until the real health check data is gathered (depends on your health check interval and the threshold), your target will become healthy state and can start to service traffic.
We can know the AWS health check systems don’t check your target at the beginning of registration, and the health checks will be started until the initial state is complete.
For example, if I configured the health check for a 30 seconds interval and required a healthy threshold of 3 to decide whether a target is healthy. It would take 3 * 30 = 90 seconds in the health check process. The worst case for a newly registered target could enter service taking 270 seconds (90 + 180 seconds). That means it would be over 4 minutes sometimes.
Similarly, it also happens on the de-registration process from NLB, so you need to take this into consideration.
Conclusion
To my customer, it’s still better for them to use ALB under the scenario, so they finally switch back to ALB and ALB doesn’t have this kind of limitation. Based on the experiment between me and our support engineer, the process on ALB is less than 20 seconds, so I think it would be an expected case to me.
If you have to use NLB and want to avoid slow provision time on your EKS cluster, you can consider to scale your environment in advance and consider the provision time into your auto-scaling strategy.



